Data Mining
Data Mining (DM) is the ad hoc application of Machine Learning (ML) algorithms to extracting knowledge or patterns from apparently unstructured data. To utilize ML algorithms for DM, one has to abstract the problem in their domain into a set of features.
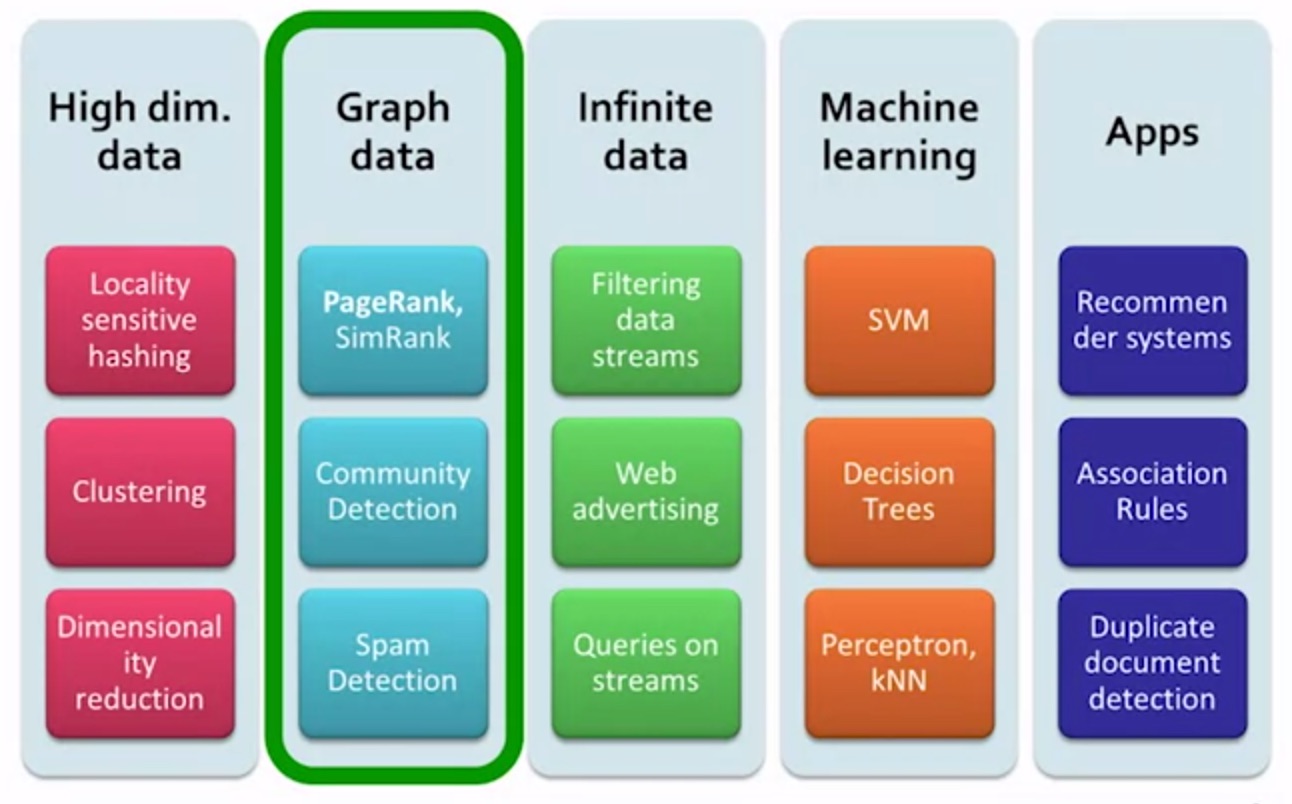 Figure: MMDS Course Overview [@Leskovec2014]
Figure: MMDS Course Overview [@Leskovec2014]
Example data mining workflow in Apache Spark:
- HDFS read: load Tweets as raw JSON
- SQL
- prepare: convert to SQL table with schema detected
- query: SQL querying (summary statistics)
- Streaming ML
- feature extraction: convert tweet content to feature vector
- train: Machine learning (k-means clusters training)
- apply: save model to file -> Streaming (clustering)
- HDFS write
Handling Off-memory Data
Distributed file systems (DFS) and MapReduce: tools for creating parallel algorithms.
Graph Data
Search engine technologies: PageRank, link-spam detection, hubs-and-authorities.
Graphs mining: social network graphs.
- constructing graph matrix from community affiliation (overlapping):
- Affiliation Graph Model (binary affiliation), BigCLAM (non-negative affiliation;
- results in K community affiliation vectors representing community topology);
- clustering (exclusive) nodes from graph matrix:
- graph Laplacian matrix (L := degree diagonal - graph matrix);
- spectral partitioning/clustering: recursively bipartite with eigenvector of L's second smallest eigenvalue; partition with higher-order eigenvectors;
Stream Data
- Stream processing: dealing with data that arrives so fast it must be processed immediately or lost.
- web advertising
Discovering Frequent Itemsets
An item is an elementary object; a basket is a set of items, aka an itemset. The frequent itemsets problem is to find itemsets that appear in many baskets.
Algorithms: association rules, market-baskets, A-Priori Algorithm and its improvements, FP-growth (frequent pattern) algorithm.
Recommendation System
Recommendation systems make recommendations based upon previously collected data. One common technique is collaborative filtering: alternating least squares (ALS).
Clustering
Finding Similar Documents: minhashing and locality-sensitive hashing.
Dimensionality Reduction
Singular-value decomposition (SVD); CUR matrix approximation (CUR); Latent semantic indexing;
Machine Learning
Perceptrons
Support-vector machines (SVM): gradient descent, stochastic gradient descent, limited-memory BFGS (L-BFGS).
Nearest neighbor
Resources
Software Platforms:
- Orange: component-based data mining and machine learning software suite, visual programming and Python bindings.
- RapidMiner, a leading open-source system for knowledge discovery and data mining, with proprietary professional edition.
- KNIME Analytics Platform, extensible open source data mining platform implementing the data pipelining paradigm (based on eclipse).
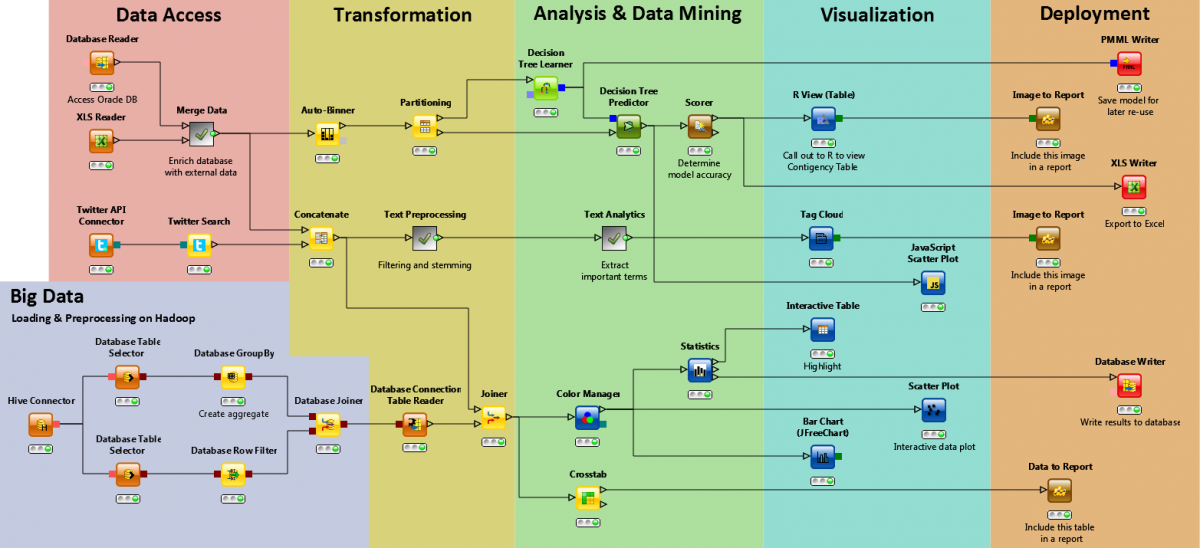 Figure: Marketing workflow on KNIME Analytics Platform
Figure: Marketing workflow on KNIME Analytics Platform